The Cold Start Problem for AI Agents: What Breaks Before You Have Data
Every AI agent has a cold start problem. On day one of production, you have no historical run data, no calibrated confidence thresholds, no labeled evaluation set, and no baseline metrics. The agent is running in the dark.
The cold start problem is temporary by definition — it resolves as data accumulates. But the decisions you make during cold start determine how long it takes to reach a reliable steady state, and getting them wrong sets you back significantly.
The three cold start risks
Over-automation before calibration. A new AI agent with uncalibrated confidence thresholds will have a false positive rate (and false negative rate) you do not yet know. Auto-acting on every high-confidence output before you understand what "high confidence" actually means in production can produce significant incorrect actions before the problem is visible.
The mitigation: start with a fully supervised mode — every output reviewed by a human regardless of confidence score. Gradually shift to automation as you build confidence in the calibration.
Missing the edge case distribution. Your test data captured the edge cases you thought to test. Production will surface edge cases you did not think to test. A new support ticket classification agent may handle the five categories you designed for correctly while mishandling a sixth category that did not appear in your test set.
The mitigation: surface low-confidence outputs prominently in the review interface during cold start, even before they cross the escalation threshold. These are your window into the edge cases you missed.
Feedback loop delay. For AI agents that learn from outcomes — a lead scoring model that improves as deals close or don't close — the feedback loop may take weeks or months to produce useful signal. The agent is running on untrained intuition during this period.
The mitigation: design the feedback mechanism before launch, not after. Make it easy for reviewers to label outputs as correct or incorrect. Even a small labeled dataset built during cold start is substantially more valuable than feedback collected months later.
The shadow mode pattern
Shadow mode is the cleanest solution to the cold start risk: run the AI agent in production but do not act on its outputs. The agent processes every real input and produces real outputs that are logged and reviewed, but human operators make all decisions.
Shadow mode lets you observe the agent's actual production behavior before any outputs have consequences. You can:
- Measure accuracy against human decisions
- Calibrate confidence thresholds against real cases
- Identify systematic errors in the edge case distribution
- Build the labeled dataset you will need for ongoing evaluation
The cost is that shadow mode requires maintaining the manual workflow alongside the AI workflow during the shadow period. This overhead is almost always worth it for high-stakes agents.
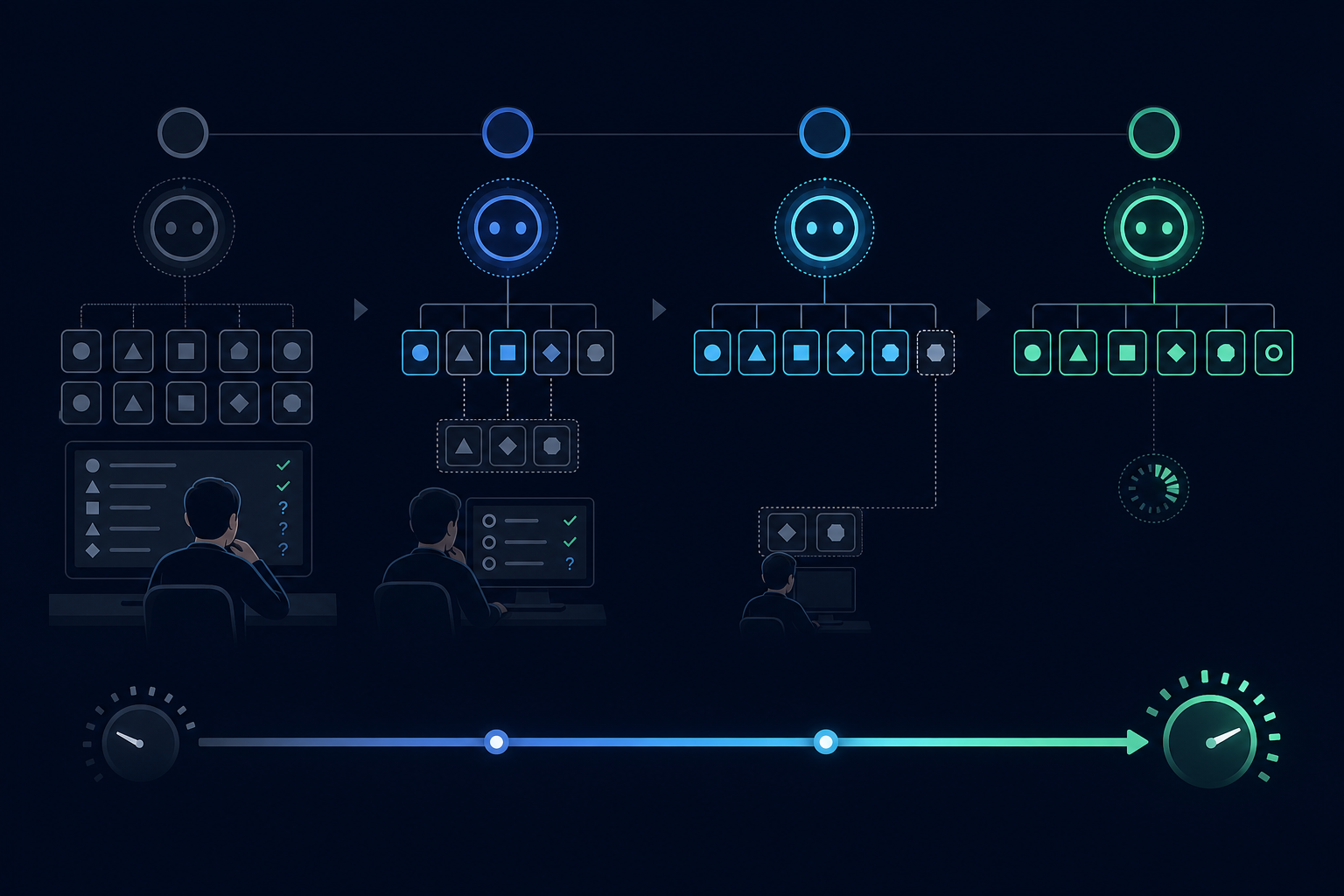
Gradual rollout thresholds
Rather than a binary switch from shadow mode to full automation, use a gradual rollout:
- Phase 1: Shadow mode, all outputs reviewed, no automated actions
- Phase 2: Automated actions on very-high-confidence outputs (95th percentile), all others reviewed
- Phase 3: Automated actions on high-confidence outputs (80th percentile), low-confidence reviewed
- Phase 4: Full automation with spot-check review
Each phase transition should be gated on a minimum sample size and a minimum accuracy rate on the previous phase's reviewed cases.
What the steady state looks like
By the time you have 1,000-2,000 real production runs labeled and reviewed, you typically have enough data to:
- Set calibrated confidence thresholds with known false positive/negative rates
- Identify the systematic edge cases that need prompt or architecture changes
- Establish the baseline evaluation metrics you will track going forward
The cold start period ends not when you decide it does, but when you have this data. Plan for it.
AgentRuntime's human task bus and run state model support shadow mode natively: every run produces a full output record and a review task, with automation level configurable per workflow type. Join the waitlist for early access.